These are my notes about Debezium. There will be typos or misunderstood concepts. Please as always reach out to me to rectify them.
My sources were Baeldung and official Debezium documentation. Also the FAQ section of the official site gives all the necessary reading.
What is Debezium?
It is an open source, low latency distributed platform for capturing change in data from a source and syncing with a target.
Why is it needed?
Most companies still use batch processing that means - a. data is not synced immediately, b. more resources are required when sync happens, c. data replication happens at specific intervals.
However, what if streaming data is used or quick reporting on the new data is required? Then we need some kind of a platform/service that periodically checks the source and when an event change occurs, it has to pick the change and transfer it somewhere for analysis or storage. Debezium as a microservice provides that functionality.
Advantages of using Debezium
- Upstream data(source) change is incrementally pushed downstream(sink) – continuous sync,
- Instant updates eliminates bulk load updates – Data transfer cost less,
- Fewer resources required,
Use cases
- Keep different data sources in sync,
- Update or invalidate a cache,
- Update search indexes,
- Data sync across microservices
Debezium
Now that we know why we need Debezium, let us go a bit in depth in its working.
Debezium as a set of distributed services capture changes in the DBs so that applications can see those changes and respond to them.
Debezium records all row-level changes within each DB table in a change event stream, and applications simply read these streams to see the changes events in the same order in which they occurred.
The beauty of Debezium is that it monitors even if the application is down. Upon restart it will start consuming the events where it left off.
Debezium also provides a library of connectors, supporting multiple DBs. Through these connectors, DBs are monitored and the changes are transported to Kakfa topics for further transporation.
Since it is distributed, it is fault and failure tolerant.
Debezium architecture
Debezium is basically a handshake service/protocol for source and target. It is achieved through connectors.
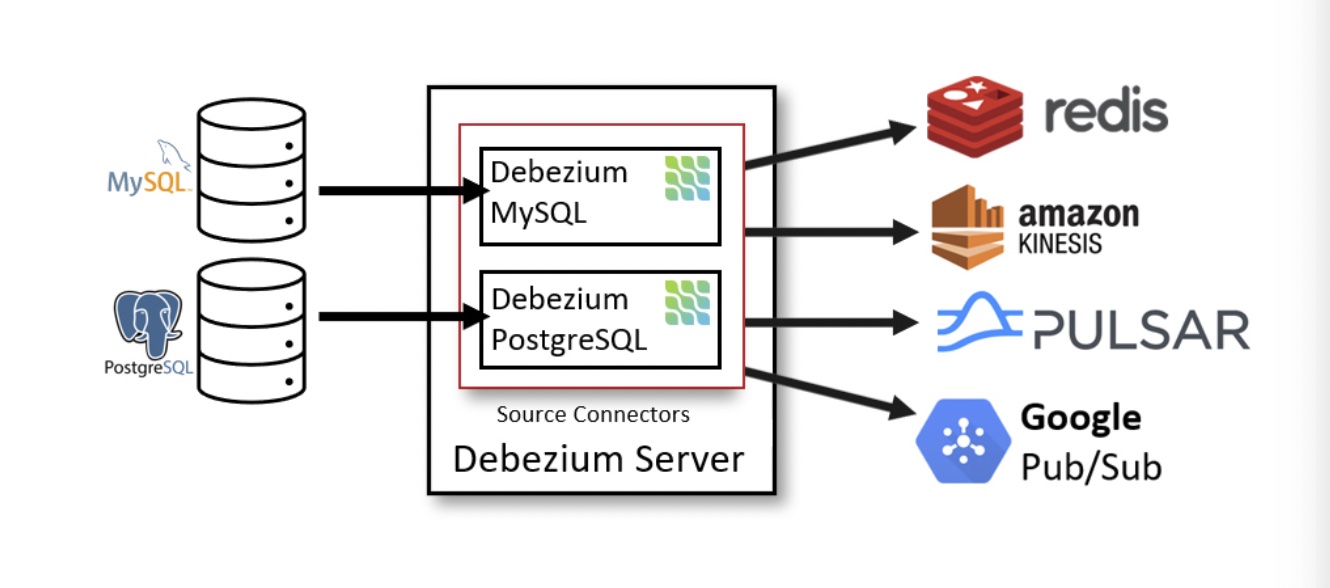
As seen in the image, Debezium architecture consists of three components – external source DBs, Debezium server, and downstream applications such as Redis, Amazon Kinesis, Google Pub/Sub or Apache Kakfa. Debezium server acts as a mediator to capture and stream real-time data change between source DBs and consumer applications.
If we look at the entire data pipeline as shown in the below image,
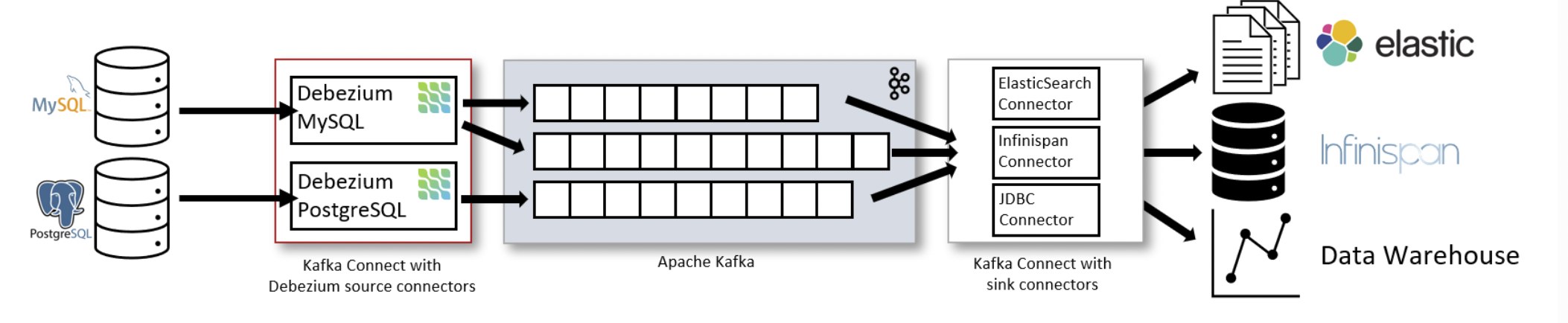
the Debezium source connectors monitor and capture real-time data updates puts them into Kafka topics. These topics capture updates in the forms of commit log, which is ordered sequentially for easy retrieval. These records are then transfered to downstream applications using sink connectors.
If Debezium connects to Apache Kafka, it generally uses Apache Kafka Connect(AKC). Like Debezium, AKC is also distributed to manage Kafka brokers.
Debezium connectors vs Kafka Connect
Debezium(DBZ) provides a library of CDC connectors whereas Kafka Connect comprises JDBC connectors to interact with external or downstream applications.
DBZ connectors can only be used as source connectors to monitor external DBs whereas AKC can be both source and sink connectors.
In Kafka Connect, the JDBC source connector imports or reads real-time messages from any external data source, while the JDBC sink connector distributes real-time records across multiple consumer applications.
JDBC connectors do not capture and stream deleted records, whereas CDC connectors are capable of streaming all real-time updates, including deleted entries.
Moreover, JDBC connections always query database updates at certain and predetermined intervals, while CDC connectors regularly record and transmit real-time event changes as soon as they occur on the respective database systems.
Connector data
The change stream consists of schema and payload.
The schema is not to be confused with DB schema. This schema describes the data types of all the fields in the payload section. Usually for JSON messages, schema is not included.
The change event data stream payload looks something like this -
change event data stream
{
"value":{
"before":null,
"after":{
"id":89,
"name":"Colleen Myers",
"description":"Nothing evening stand week reveal quickly man traditional. True positive second because lose detail.\nNice enough become woman then staff along. Life receive account. Many exist data thousand.",
"price":98.0
},
"source":{
"version":"2.2.0.Alpha3",
"connector":"postgresql",
"name":"debezium",
"ts_ms":1692626411411,
"snapshot":"false",
"db":"postgres",
"sequence":"[\"23395760\",\"23395904\"]",
"schema":"commerce",
"table":"products",
"txId":847,
"lsn":23395904,
"xmin":null
},
"op":"c",
"ts_ms":1692626411879,
"transaction":null
}
}This is for inserting an data entry. For an update the stream looks like -
{
"value":{
"before":{
"id":95,
"name":"Steven Cowan",
"description":"Heavy rise something sell case institution chair. Control them might court surface none property. Subject behind them. Quickly near trial.",
"price":75.0
},
"after":{
"id":95,
"name":"Yvonne Collins",
"description":"Heavy rise something sell case institution chair. Control them might court surface none property. Subject behind them. Quickly near trial.",
"price":75.0
},
"source":{
"version":"2.2.0.Alpha3",
"connector":"postgresql",
"name":"debezium",
"ts_ms":1692626421005,
"snapshot":"false",
"db":"postgres",
"sequence":"[\"23399328\",\"23399456\"]",
"schema":"commerce",
"table":"products",
"txId":854,
"lsn":23399456,
"xmin":null
},
"op":"u",
"ts_ms":1692626421499,
"transaction":null
}
}- 1
- LSN- Log sequence number. An unique number for every change entry. Used to track and order transactions and changes within the transaction log.
Streaming Changes - PostgreSQL
The PostgreSQL connector typically spends the vast majority of its time streaming changes from the PostgreSQL server to which it is connected. This mechanism relies on PostgreSQL’s replication protocol. This protocol enables clients to receive changes from the server as they are committed in the server’s transaction log at certain positions, which are referred to as Log Sequence Numbers (LSNs).
The Debezium PostgreSQL connector acts as a PostgreSQL client. When the connector receives changes it transforms the events into Debezium create, update, or delete events that include the LSN of the event. The PostgreSQL connector forwards these change events in records to the Kafka Connect framework, which is running in the same process. The Kafka Connect process asynchronously writes the change event records in the same order in which they were generated to the appropriate Kafka topic.1
Setting up permissions
Use this link to set up permissions.
Create Debezium user with minimum privielges to avoid security breaches.
Postgres source connector config
pg-src-connector.json
{
"name": "pg-src-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "postgres",
"database.server.name": "postgres",
"database.include.list": "postgres",
"topic.prefix": "debezium",
"schema.include.list": "commerce"
}
}- 1
- a postgres DB connector
- 2
- DB’s configurations
- 3
- Kafka topic prefix that is used in Kafka topic.
- 4
- The tables in the schema the server monitors for changes
So the Debezium server will monitor postgres DB as user postgres and the same password at port 5432 on the tables in schema commerce.
The kafka topic prefix is debezium, the schema commerce which has two tables - products and users.
So, the connector would stream records to these two Kafka topics:
debezium.commerce.productsanddebezium.commerice.users
read more on topic names here.
Postgresql on AWS RDS
Using this link.
Common issue with Decimal data types
Debezium that uses Kafka connect serialises decimal values for Kafka connect to understand. That means Debezium, converts to BigDecimal binary and encodes in Base64. At the output or downstream, onus is on the user to decode and convert back to the original value.
So, a decimal or numeric data type at the source, will become something like eA== as it passes through Debezium and reaches Kafka topic.
A possible solution is to use REAL data type in SQL. However, this might not be possible in many real-life scenarios. Hence, a property decimal.handling.mode in connector can be set to either string or double. In string case, proper de-serialiser has to be implemented at the receiver. With double precision is sometimes lost.
It is quite a conundrum. Read more on this issue and solution here, here and here.
Footnotes
https://debezium.io/documentation/reference/stable/connectors/postgresql.html#postgresql-streaming-changes↩︎